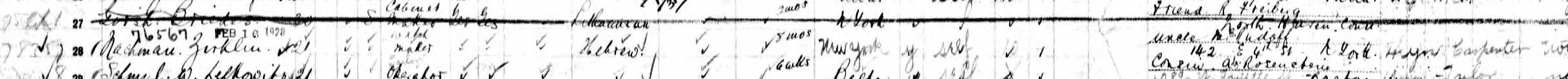“THE EDITUR OF THE TIMES PAPER
Sur, — May we beg and beseech your proteckshion and power. We are Sur, as it may be, livin in a Wilderniss, so far as the rest of London knows anything of us, or as the rich and great people care about. We live in muck and filth. We aint got no priviz, no dust bins, no drains, no water-splies, and no drain or suer in the hole place. The Suer Company, in Greek St., Soho Square, all great, rich and powerfool men, take no notice watsomdever of our complaints. The Stenche of a Gully-hole is disgustin. We all of us suffer, and numbers are ill, and if the Colera comes Lord help us.Some gentlemans comed yesterday, and we thought they was comishioners from the Suer Company, but they was complaining of the noosance and stenche our lanes and corts was to them in New Oxforde Strect. They was much surprized to see the seller in No. 12, Carrier St., in our lane, where a child was dyin from fever, and would not believe that Sixty persons sleep in it every night. This here seller you couldent swing a cat in, and the rent is five shillings a week; but theare are greate many sich deare sellars. Sur, we hope you will let us have our complaints put into your hinfluenshall paper, and make these landlords of our houses and these comishioners (the friends we spose of the landlords) make our houses decent for Christions to live in. Preaye Sir com and see us, for we are living like piggs, and it aint faire we shoulde be so ill treted.
We are your respeckfull servents in Church Lane, Carrier St., and the other corts. Teusday, Juley 3, 1849.”
This letter was signed by fifty-four residents of the St Giles ‘rookery’ in London. Published on 5 July 1849 under the headline ‘A Sanitary Remonstrance‘.
***
The rapid expansion of our large industrial towns and cities started in the eighteenth century but was particularly so during the first half of the nineteenth, as increasing numbers of people migrated from rural areas and from Ireland. Between 1800-1850 the percentage of English citizens living in urban areas in the country as a whole increased from 30 to 50%, but in certain major industrial towns the growth was much greater. In Birmingham, between 1801 and 1851, the population increased from 71,000 to 233,000. In the same period Liverpool’s population grew from 82,000 to 376,000. In just one decade from 1821-31 Bradford’s population increased by 78%.
How on earth did these towns cope with housing and facilities for all these additional people? The simple answer is that they did not.
The thinking was that needs would be served by demand: employers would build factories, and speculative builders would build the housing needed for the incoming labourers. Of course the builders required a profit for their work, and the problem was that the workers were paid very little. Even the cheapest housing meant some workers were paying a quarter of a very meagre income on rent. By the end of the nineteenth century, nearly one third of the population would be considered ‘the very poor’.
There were several consequences. One was that purpose-built housing for the masses was of very poor quality, often built with just twenty or so years left on a land lease and deliberately built to last for just that length of time. Walls were the thickness of a single row of bricks, and the bricks themselves were often insufficently fired. Proper foundations were not dug out, meaning floor boards on the lower levels could be laid just a couple of inches above bare earth. In the Midlands and the North, back-to-backs became common. Each house had a party wall on three sides, with the door and windows only on the remaining side. Sometimes these were built in rows along parallel streets, but often they were arranged around courtyards, with the outer properties facing the street and the (cheaper) inner properties accessed via an alley or tunnel. Consequently, not only was there no possibility of air flow from one side of the house to the other, but the courtyard itself would have very little movement of air.
Room sizes were small, and despite the generally large family sizes, most purpose-built housing for the labouring classes had just two rooms: one up and one down, plus possibly an attic space. In the 1870s 43% of married women had 5 to 9 children; 18% had more than ten children. Hence as a matter of course, most individual family homes for the workers would be overcrowded.
As an alternative there was the option of repurposing existing housing. The large family homes built in the Georgian period for better-off families might now be sub-divided, with rooms on each floor let to different families. Repurposing in this way was always cheaper than purpose-built, but it did mean that the facilities and level of privacy originally intended for one family were now to be shared amongst several.
For the poorest of all, these already inadequate spaces were shared. Two, three or even more families would share small houses, designated rooms on a floor, or even one room.
Worst of all, the cellars of larger houses were rented out as dwellings – and even they might house more than one family. Some families even kept livestock in a pen alongside the family. There was, of course, no drainage. What’s more, the floors were bare earth and often they were below the water table, meaning they regularly flooded.
As the nineteenth century progressed and towns prospered, local authorities started to erect grand buildings as a testament to civic pride. Roads were widened to facilitate easier passage of large numbers of hansom cabs, and towns were redrawn to make way for railway lines and their stations. All of this required clearance of existing housing, and often the routes and locations selected specifically targetted the housing of the working classes. This was generally thought to be a good thing, since the housing was filthy, a health hazard and an eyesore. However, no new housing was built. Consquently, these grand developments meant worse overcrowding since more families had to cram into the buildings that remained. There were also raised rents, since unscrupulous landlords sought to take advantage of the scarcity of housing. In London, 120,000 people were displaced, and no new housing built to accomodate them.
Vast ‘rookeries‘, already unfit for human habitation, were the only areas available for the very poor. These were characterised by narrow alleyways and poorly-constructed multiple-storey dwellings crammed into whatever space was available. St Giles in London, where the signatories of the above letter to The Times lived, was a rookery. So too was the ‘Devil’s Acre’: the land on which Victoria Street in Westminster was built.
To this perfect storm of poor quality, inadequate housing, overcrowding and lack of ventilation, we must add one more fact of life: People need toilets.
The flushing toilet, or water closet, depends upon ready availability of water and a system of sewers, but it was not until the middle of the nineteenth century that these started to be installed as standard. Prior to that there were dry closets neutralised by earth or ashes; and cess pits. ‘Night soil’ would be collected by men whose job it was to take it to market gardens outside the towns, where it could be used as fertiliser. In some houses the cess pit was actually in the cellar, so that waste collected immediately below the floor boards of the ground floor dwelling rooms. Perhaps it was the rapid growth of towns and cities that meant these arrangements did not always go to plan, but we do know that collection of sewage and general waste was not always carried out. In one infamous rookery in Leeds called the Boot-and-Shoe Yard, no waste was collected for more than six months. When eventually this was remedied, over seventy cart loads were taken away. In any case, privies were shared between households – maybe as many as three hundred people, although the St Giles signatories claimed to have none at all: “We live in muck and filth. We aint got no priviz, no dust bins, no drains, no water-splies, and no drain or suer in the hole place.”
In 1842 serious concerns about the insanitary conditions in Leeds’s Boot-and-Shoe Yard led to the demolition of this rookery just off one of the main streets in the town. The 1841 census is therefore the only snapshot we have of the number and occupations of the residents. As can be seen from this extract, many of them were migrants from Ireland.

Citation: 1841 Census of England and Wales. Original data: The National Archives. Source: Find My Past – the ‘I’ in the last column indicates those who were from Ireland
The popular view was that the muck and filfth was the fault of the residents, whose standards, lifestyle and morals were unacceptable.
It wasn’t until well into the second half of the nineteenth century that change gradually came. Prior to this there were no planning laws or building regulations. Gradually, local authorities were empowered to require builders to conform to certain minimum requirements, but many did not act on this because of the extra cost to the ratepayer. Increasingly it came to be understood that the health crisis and the housing crisis were two strands of the same issue, and permissive powers evolved into mandatory, but it would take the slum clearance and demolition programmes before finally these living conditions were consigned to the history books.
How can we make use of this information in our family history research?
Armed with this understanding of living conditions we can look for clues to learn more about the conditions in which our ancestors lived. Often, but not always, the worst conditions were occupied by immigrants. Here are some ideas:
Look for multiple households at one address in the census
In this extract from the 1901 census we see three households including 23 people living in one house. In fact this is only part of the return for number 5 Brick Lane: the rest are recorded on the following page. In total there are four households totalling 31 people. Three of the households have lodgers – a total of five lodgers altogether in the house.

Citation: 1901 Census of England and Wales. Original data: The National Archives. Source: ancestry.co.uk
Look for families living in cellars
The houses in Liverpool’s Edmund Street had cellars, and as with many of the larger properties in Liverpool, these were let as separate dwellings. The main house at number 56 is a lodging house, with five lodgers, but another family is recorded in the cellar.

Citation: 1851 Census of England and Wales. Original data: The National Archives. Source: ancestry.co.uk
Use the largest scale maps you can find to identify yards or courtyards, especially with back-to-backs
This small section of Lee’s Square is taken from an 1850 map of Leeds. Unfortunately the rest of the Square is on the next Ordnance Survey sheet. Thanks to the large scale of this map we can see individual properties. What we see is that most of the properties in Lee’s Square are back-to-backs. The property behind each abode has the door and windows looking out on to the street. The rents for those properties will be slightly higher. Although we can’t see from this map section, the privy will be inside the Square, also the water pump. This, added to the obvious lack of free-flowing circulation of air, will mean the inner properties are less healthy places to live than the outer.

Citation: Ordnance Survey Town Plan of Leeds, Surveyed 1847, published 1850. Reproduced with the permission of the National Library of Scotland. [Click here] for link to the full map.
Look for old photos of the addresses where your families lived
Ideally, you’ll be able to compare these with contemporary maps. The image below shows the same portion of Lee’s Square as you see on the map above. You can see the two sets of steps leading to the doors of two of the houses, and a cellar of some sort below. The photo is dated 1901 – fifty years after the map was surveyed and published, and the lean-to appears to have been added in the intervening years. The buildings on the southern side of the square seem to be lower and perhaps don’t have the substructure. This is of particular interest to me because my 2x great grandfather was living here in the 1890s. Thanks to a Coroner’s Report after his death I know that his house was above a stable, but it isn’t clear from this photo or its partner (looking east) where the dwellings above a stable would be.

Citation: ‘Lee’s Square looking west, 1901’ Source: Leodis. [Click here] for link to image on Leodis website.
If you have ancestors who might be classed as ‘urban poor’ in the nineteenth century, I hope these ideas will help you.
All of this new research has been carried out as part of my One Place Study for Shackleton’s Fold.
I’m also developing a presentation on the subject of Housing the Urban Poor in 19th Century England. If this is of interest to you and your local or family history society, please take a look at my Public Speaking page, and follow the link at the bottom of that page to contact me.
***
Sources
David Olusoga & Melanie Backe-Hansen: A House Through Time, 2021. Picador, London
John Burnett: A Social History of Housing 1815-1970, 1978. David & Charles, Newton Abbot
Stanley D Chapman (Ed): The History of Working-Class Housing, 1971. David & Charles, Newton Abbot – this book has separate chapters on London, Glasgow, Leeds, Nottingham, Liverpool, Birmingham, South-East Lancashire/ Pennines, Ebbw Vale.
B R Mitchell and Phyllis Deane: Abstract of British Historical Statistics, 1962. Cambridge University Press.