The Genealogical Proof Standard is an internationally accepted guide for establishing the reliability of a conclusion reached in genealogical research. It’s a vital concept for professional genealogists, but all family historians should be aiming for this standard. After all, our goal should always be to ensure the people we’re researching are actually our ancestors.
There are five elements to the Genealogical Proof Standard:
- Reasonably exhaustive research
- Complete and accurate source citations
- Analysis and correlation of the collected information
- Resolution of any conflicting evidence
- A soundly reasoned, coherently written conclusion.
In today’s post I’m going to work through an example to illustrate the first, third, fourth and fifth elements. Discussion of citations will follow in my next post.
My research objective here is to answer this question:
What happened to Mary Ann Ingham after the death of her parents?
Mary Ann is my 2x great aunt. I first came across her about twenty years ago, in the relatively early years of online genealogy records. I lost track of her following the death of her parents. I do like to follow through on siblings of my direct line, but back then, Death Certificates were available only as paper copies, and the cost of buying speculative certificates for siblings of my ancestors was prohibitive. Today, a digital download of the same information costs just £3. So it’s time to take another look…
What I already know about Mary Ann
- Mary Ann is the older sister of one of my great grandmothers, the second of six children born to my 2x great grandparents. Her entry on the GRO online Birth Index indicates that her birth was registered in the December quarter of 1850 in Hunslet. This means it was registered between 1st September and 31st December, but the birth could have been up to six weeks before that.
- 1851 Census. Mary Ann’s age is recorded as 5 months. The date of the 1851 Census was Sunday, 30 March 1851, suggesting she was probably born in October 1850. It may be a couple of weeks out, but it’s good enough for my needs.
- 1861 Census. Mary Ann is ten years old. In the final column, where information is requested regarding whether any person is ‘Blind, or Deaf-and-Dumb’, we learn that Mary Ann has been ‘Deaf from Birth’.
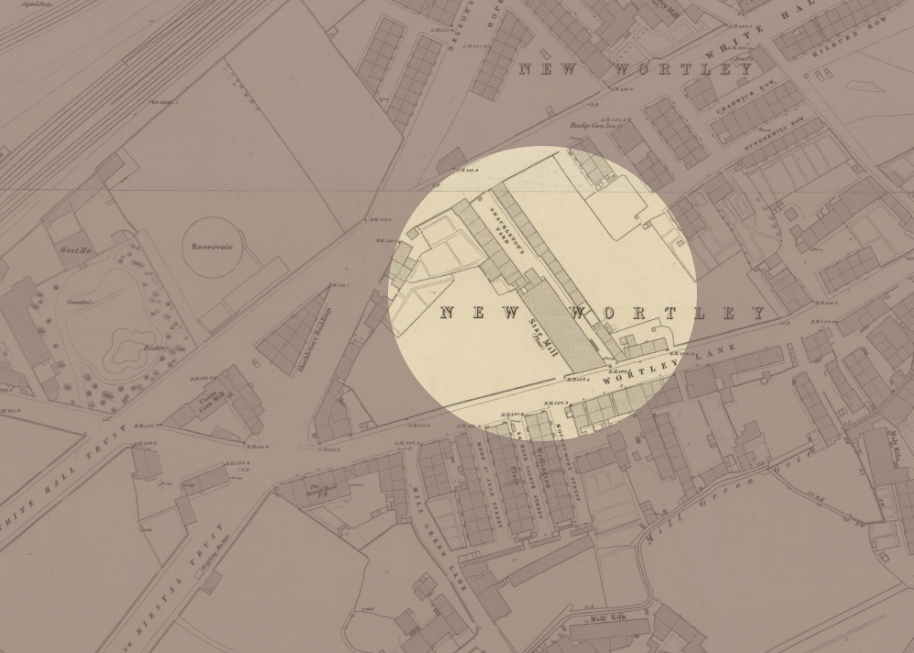
- 1871 Census. The family have moved from Hunslet to New Wortley. Oldest sister Maria has married, and two younger siblings have died since the last census. Mary Ann, aged twenty, is listed without an occupation. Possibly this is because of her deafness. Her mother is listed with an occupation outside the house, suggesting that it is Mary Ann who takes care of the house.
- 1881 Census. Only Mary Ann and the youngest sister are now living at home with their parents. Both daughters are employed as Cloth Finishers.
- 1991 Census. The youngest sister has married and moved away. Mary Ann, now forty years old, is living at home with both parents. She has no occupation outside the home, and once more the final column includes the information that she has been ‘Deaf from childhood’.
- Mary Ann’s father died in October 1892, and her mother in July 1894.
*****
My ‘Reasonably Exhaustive Research’
First, what are the possibilities?
- Mary Ann might have married after 1894. She was only 43 years old when her mother died, and first marriages at this age, perhaps to a widower, were not uncommon. If she did marry she would be recorded on the 1901 Census with a different surname. However, Mary Ann’s deafness does seem to have been a significant disability for her.
- She might have died before the next census, 1911.
- She could still be single in 1911, recorded on the census with the same name, and living alone or with another person or family.
Her immediate whereabouts was soon established when a search on Ancestry found her living in 1901 with her older sister Maria, plus Maria’s husband and family. She had been there all along, of course, and I had that record linked to Maria and her family. However, because Mary Ann was recorded on that document as ‘Sister-in-Law’ to the head of household she wasn’t included when the record attached automatically to family members. Twenty years ago I missed this; and of course after all this time I had forgotten.
Perhaps this living arrangement might have continued, but in January 1903 sister Maria died. What happened next?
Q. Did Mary Ann move in with either of her surviving sisters and their families?
A quick check on the 1911 Census for both of these indicates that, certainly by 1911, she was not living with either of her sisters.
Q. Is Mary Ann on the 1911 Census elsewhere – alone or with someone else?
No. Searches on Ancestry and FindMyPast for Mary Ann Ingham, born 1850 +/- 2 years in the Leeds area returned no searches.
Q. Did Mary Ann marry?
Searches on Ancestry, FindMyPast and FreeBMD for a marriage for Mary Ann Ingham, between 1901 and 1921 and in the Leeds area (using several local Registration District names for FreeBMD) returned two records:
- A Mary Ann Ingham married either John Bradshaw Mann or Charles Watson April-June 1903. The other man married Annie McCaragher
- A Mary Ingham married John Hardaker January-March 1904
Digital images of these marriages are not available online, nor as digital downloads. Therefore without buying the civil records (which I did not want to do, as each would cost £12.50) I needed to identify these people using other online records, and find a way to discount some or all of these marriages.
A search on Ancestry for Charles Watson, location Hunslet, and filtering for any record between 1901-1911 returned the following birth record:
Charles Hilary Watson’s birth was registered October 1906 in Hunslet. Keying these details in at the GRO online Birth Register index, I found that the mother’s maiden name was McCaragher. I now know that Charles Watson married Annie McCaragher, therefore it was John Bradshaw Mann who married Mary Ann Ingham in 1903.
A search on Ancestry for John Bradshaw Mann, location Hunslet, and filtering for any record between 1901-1911 indicated that this couple too had named their firstborn child after the father, and the GRO website confirmed that the mother’s maiden name was Ingham. I now had a birth year for a family member: 1906, and could use this additional information to locate the family. Although it was extremely unlikely (to say the least) that my now 55 year-old 2x great aunt Mary Ann would have given birth, finding the actual age of the Mary Ann that married John Bradshaw Mann would enable me to discount this marriage. A search of the 1911 Census for John Bradshaw Mann, location Hunslet and birth year 1906, proved fruitless. However, by removing the ‘Bradshaw’, 5 year-old John Mann was located, along with his father John Mann and his mother Mary née Ingham. Mary was born in Hunslet but was only 31 years old. This is not my Mary Ann.
A search for John Hardaker, also for Mary Hardaker after the marriage, proved more difficult:
- Since the birth of children had proved to be a fast-track method of discounting the marriages so far, a search was carried out on the GRO online Births index for a child with the surname Hardaker and mother’s maiden name Ingham, any location, for the years 1904 to 1920. This search was carried out for females and males. There were no births.
- Next a search on Ancestry and FindMyPast for Mary Ann Hardaker, born 1850 +/- 5 years. This search filtered first for the 1911 Census and then on Deaths 1904-1914. There were no records.
- Then a search on Ancestry and FindMyPast for John Hardaker. With no year of birth for John, the birth year search parameters were set for 1830 to 1870. There were some John Hardakers on the 1911 Census but none had a wife named Mary.
This search was inconclusive. A John Hardaker had married a Mary Ingham in 1904 but they seem to have disappeared. That said, my Mary Ann has consistently been referred to in all records located to date as ‘Mary Ann’, rather than simply ‘Mary’. On this basis it seems likely that this is not my Mary Ann, but that does not amount to evidence either way.
Q. Did Mary Ann die before the 1911 Census?
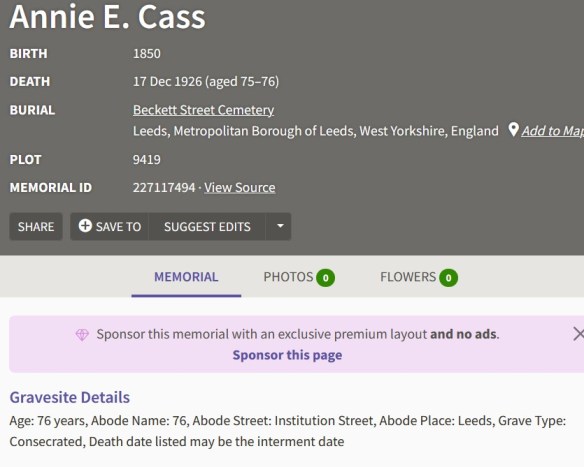
A search for Mary Ann Ingham on the GRO online Death Index for the years 1903 +/- 2 years and 1907 +/- 2 years signposted the following record. The details were generally a good fit for Mary Ann, although the age is two years out. I paid my £3 and downloaded the image. If the informant – the person reporting the death to the Registrar – was a family member whose name I recognised, I would know for sure that this is my Mary Ann. Unfortunately this was not the case. Mary Ann died at a local infirmary after a fall, and the informant was the Coroner for the City of Leeds. (Click for BIG)

Residences
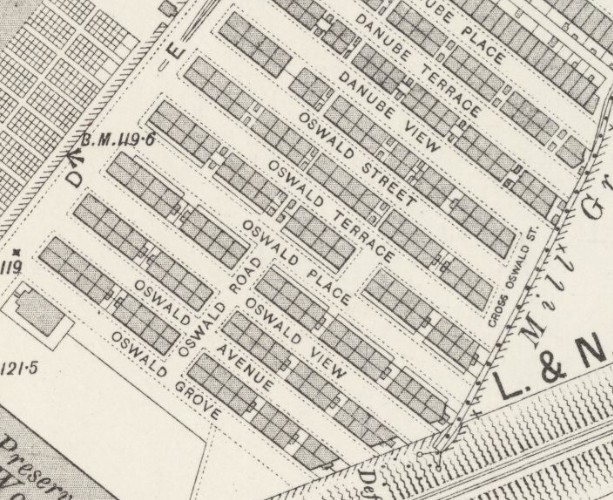
Can we ascertain anything from the usual address of the late Mary Ann Ingham on this Death record? She was living at 22 Oswald Place in New Wortley. We can compare this to other records for herself and the two Ingham sisters, Maria and Jane:
- In 1901 Mary Ann was living with her sister Maria and family at 22 Oswald Terrace.
- In 1901 sister Jane and her family were living at 12 Oswald Place. They would be at the same house in 1911 and 1921. This is a close family!
- After Maria’s death, her husband is recorded as living in 1904 at Danube Terrace.
- Therefore the usual residence of Mary Ann in 1909, as given on her Death Certificate, is just a few doors from her sister Jane.
This is not ‘proof’ that this Mary Ann and my Mary Ann are the same person. However, it does add weight to the likelihood.
Mary Ann’s burial
Finally, a search on the FindAGrave index gave me the definite proof I was looking for. It revealed that this Mary Ann Ingham, who died on 11th December 1909, was buried on 17th December 1909 at New Wortley Cemetery. This is the same cemetery where my 2x great grandparents had been buried in 1892 and 1894. The records reveal that Mary Ann was buried in the same plot as her parents.
*****
Analysis and correlation of the collected information
It was important to start by establishing all of the possibilities, and then to work through them until such time as one established the certainty I was looking for. It was almost certain that Mary did not marry after 1901, yet she was not located on the 1911 Census as Mary Ann Ingham. We must always be aware of faulty transcriptions and missing entries, therefore the absence of a record is not in itself proof.
Moving on to the Death record, this was generally a reasonable fit for Mary Ann. However, the age is wrong: Mary was 59 in December 1909, not 61. This, together with the absence of a family member on the record meant it too did not provide certainty, although combined with the information about addresses it pointed to a ‘strong likelihood’ that this was my Mary Ann.
Although I could say the research carried out to get to this point had been reasonably exhaustive, there would have remained the possibility that my conclusion was not correct. In such cases we must always be receptive to any new information, and be prepared to review and change our interim conclusions. I could, for example, have accepted this as the likely death for Mary Ann, but could have reviewed newspaper archives for any news items about the death, or about the Coroner’s Inquest. I could also have explored whether the Coroner’s notes were available at West Yorkshire Archives. The truth is that, for a 2x great aunt, I would probably not have ever got around to doing this, but there might have been other circumstances where having absolute proof was important.
In the event, none of this was necessary. The final piece of evidence is that the Mary Ann who died on 11th December 1909 was buried one week later in the same plot as my 2x great grandparents, Mary Ann’s parents. This is certainly my Mary Ann.
*****
Resolution of any conflicting evidence
The only part of the evidence that is actually conflicting is Mary Ann’s age at death. It can be explained by the fact that the information was given by a family member – perhaps sister Jane, or perhaps one of Mary Ann’s brothers in law, or the younger sister who lived a short distance away, also in New Wortley. The person giving this information made a mistake. As a piece of conflicting evidence it no longer matters, since we have found our actual proof via other documentation.
That said, there was a lot of conflicting information in the hints showing up on Ancestry.co.uk. These hints formed two completely different ‘stories’. First, another Mary Ann Ingham of almost exactly the same age, living in an area that ‘made sense’ in the context of the Ingham family’s movements, and with the same father’s name, was married at Leeds parish church in 1867. It would have been easy to fall into the trap of accepting this as my Mary Ann, and giving her a completely false life, were it not for the fact that (a) records showed that my Mary Ann was still living with her parents, and (b) there was just one detail on the marriage record indicating that this was a different family: the father’s occupation was different.
The second lot of hints consistently confused Mary Ann with her older sister, Maria. In fact none of the hints actually related to the correct Mary Ann Ingham.
This illustrates and emphasises an important point:
Information on hints and on other people’s online trees is never ‘reasonably exhaustive research’.
People make mistakes. Hints are, at best, just ‘hints’: suggestions. They are there for you to explore and see if you agree, but they are based on what other people with the same family names have added to their trees. Unfortunately, the more people who accept this often false information and add it to their trees, the more determined the algorithms will be to persuade us that the records on offer are the right ones.
*****
A soundly reasoned, coherently written conclusion
The analysis above supports the conclusion that Mary Ann Ingham died on 11th December 1909. After the death of her mother in 1894 Mary Ann lived with her sister Maria and family, and afterwards seems to have lived very close by her sister Jane, but not in the same house. Reading between the lines, Mary Ann’s deafness seems to have prevented her from living life to the full outside the family, to the extent that she seems, at some point, to have taken on the main household duties while her mother earned a little money away from the home. Mary Ann’s sisters seem to have looked out for her, and it is touching that they had her buried with their parents. It would be interesting to explore what deafness from birth meant for a person in the second half of the nineteenth century. What assistance and education would have been available? Was Mary Ann able to attend a school offering facilities for deaf children? Or perhaps she had no education at all.
*****
The final point to make here is that this was necessarily a fairly straightforward example of ‘Reasonably Exhaustive Research’. The wealth of records we have after the introduction of Civil Births, Marriages and Deaths in 1837, and with the advent of the decennial Census, alongside the parish records and other documents such as Coroners’ Inquests, newspaper accounts and so on, means we can generally be sure when our search has been reasonably exhaustive. Earlier than this, it gets harder. ‘Reasonably Exhaustive’ may run into scores of hours, and in the end may not find an answer, or may result in a ‘likelihood’ rather than proof. Nevertheless, the principles are the same: Set your objective; Define your questions; Search, Analyse, consider any Conflicting Information, and be prepared to Revise your Conclusions if new information comes to light.