
I’ve often heard people who are interested in their family history say they won’t take a DNA test because they’re not interested in connecting with 3rd or 4th cousins: they just want to know about their own ancestors. This is a misunderstanding of how DNA matching works. The point is that we share 2x great grandparents with our 3rd cousins, and we share 3x great grandparents with our 4th cousins. Unless our ancestors have lived extraordinarily long lives and reproduced the following generation at scandalously early ages, none of those ancestors of ours will still be living. However, if we can connect with other people who are descended from them via siblings of our direct line, we might learn new stories about them that were passed down their line but not ours. We might even find new photographs or documents, or a family bible. If we’re not absolutely sure that we have the correct parentage assigned to one of our forbears, the DNA will prove that and help us to work out who the correct person is. If all this seems like an impossible puzzle – well, yes, there is a lot to learn. Sometimes the connection is very clear; other times we have to work hard to find it. But it’s worth it.
In my own family research I’ve used DNA to home in on birthplaces in Ireland (from where my ancestors migrated before the advent of civil registration and before the big fire in Dublin); to verify a hypothesis I had about a mysterious ancestor; to help several other people to find missing grandfathers; and to connect with people who had photos. However, this post is not about my own ancestry.
Today I’m going to share with you how I used three unknown DNA matches of a person whose DNA I manage:
- to identify beyond doubt the birthplace in modern-day Belarus of certain named individuals;
- to identify beyond doubt two family members, brothers of direct ancestors, about whom very little was known.
All this is published here with that person’s permission.
The case is complicated because it involves several countries, constantly changing national boundaries, two continents, several languages and two types of script: the Latin script we use in English, and the Cyrillic script used in Russia and Belarus. It involves people of Jewish heritage, where the high incidence of endogamy can skew estimates of cousin matches, making them appear closer than they really are. At no time did I make contact with any of the DNA matches. All research was carried out using only the sparse information they each had on the trees linked to their DNA results as my starting point.
The research relates to Marks Chirklin, his wife Fanny Chirklin née Rudow and one of their daughters, who I will not name here.
The Chirklins immigrated to the UK early in the twentieth century, and were believed by their living descendants to have come from Poland or Lithuania. In the 1911 census their country of birth is recorded as ‘Russia’. None of this is incompatible, since boundaries changed regularly. However, the Russian Empire was huge, so this documentary evidence did nothing to permit a homing in on the actual birthplace of the family.
In all UK records the name of this family is written as Chirklin or Cherklin. This too is not without complications. For any of our ancestors originating in a non-English speaking country, names may have been anglicised. If they have come from a place where an alphabet other than our Latin script is used, the complications are even greater. Often in such cases we lack a letter to write the sounds required to pronounce the original word. In the case of immigrants this will impact on names of people and also place-names. As we shall see, both of these were an issue in this research.
Using records and DNA matches to locate a birthplace for the Chirklins
In the 1921 UK census Marks and Fanny gave their birthplaces as Vilna. Vilnius is the capital of Lithuania, but ‘Vilna’ is a government district, or ‘Oblast’. Although it did include Vilnius, it was much larger, including territories in present-day Belarus as well as Lithuania. At the time the family came to the UK it was part of the Russian Empire.
However, in the same census, the now-married daughter of Marks and Fanny gave her birthplace as ‘Dishna, Russia’. This was problematic for the linguistic reasons outlined above. Just writing this down involved transforming the sounds of her homeland and somehow finding a way to make sense of these sounds in English language and script. So ‘Dishna’ was unlikely to be entirely correct, but it was a starting point; and since the rest of the family were born in the Vilna Oblast, this narrowed down the search for a town within Vilna with a name that sounded like ‘Dishna’.
I had already noticed that the Chirklin descendant whose DNA I manage had two reasonably close DNA matches with names in their trees similar to Chirklin. Specifically, those names were Tsirklin and Tzerklin. One was in the US; the other location not known. Both were showing with a probability of a 2nd-3rd cousin match. For reasons outlined above, this estimated match level needed to be taken with a pinch of salt to some extent. Even so, a DNA match stretching back far enough to be just out of reach as far as our UK and US records are concerned seemed likely – perhaps a 3rd-4th cousin match.
Should my linking of Chirklin, Cherklin, Tsirklin and Tzerklin require any explanation, it’s easily explained by the linguistic conversion of the sounds of one language family to another. There is often even a difference between the way surnames were recorded upon immigration into the US and immigration into the UK. (For example the name pronounced phonetically in the US as Pet-Raow-Skee is both spelled and pronounced differently in the UK: Piotrowski and Pee-Ot-Roff-Skee.) In a new language which doesn’t have an equivalent sound, ‘Tz’ could easily be the same sound as ‘Ch’.
I had no way of knowing how these Tsirklins and Tzerklins were connected to the Chirklins. The family trees linked to the DNA results were sparse, and it seemed clear that any connection would be back in the old homeland. What I could see, however, was that the earliest known Tsirklin was from ‘Volintsi’ in Belarus, and the earliest known Tzerklin from Polatsk in Belarus. These towns are about 35 km apart – but Polatsk is a much larger town and could easily have been a ‘shorthand’ for “I come from a tiny settlement called XXX about 10 miles from Polatsk”.
Locating these on the map I then searched for ‘Dishna, Belarus’ and found it: Dzisna – just a short distance south of Volyntsy. By combining the documentary evidence of the placename given on the 1921 census with the location of these reasonably close DNA matches with the same family name, we finally had a definite birthplace for this Chirklin daughter and possibly for her siblings and parents too.

There are various spellings of this town’s name. I have come across Disna, Dysna, Dzisna (Polish), but also in the Russian Cyrillic script Дзісна in Belarusian (which is pronounced Dzisna, as in the Polish pronunciation), and Дисна in Russian, which would be pronounced as Disna. Today, the boundaries of the Oblasts have also changed. Dzisna is now within the Molodechno Oblast of Belarus.
Using records and a third DNA match to identify and locate two missing family members
In addition to the known siblings living with the family at the time of the censuses, the Chirklins were thought to have another son: Nathan. The descendants of the family knew of him only from a reference on a memorial headstone. He was generally assumed to have gone to America, but no one knew for sure. One of the descendants found a new document via Ancestry.com, and thought this could be him.
The new document was a ship’s manifest, dated 1907, including the passenger Nachman Zirklin. Could ‘Zirklin’ be yet another anglicisation of Chirklin/ Cherklin/ Tzerklin/ Tsirklin? And could ‘Nachman’ be the missing person thought to be Nathan?
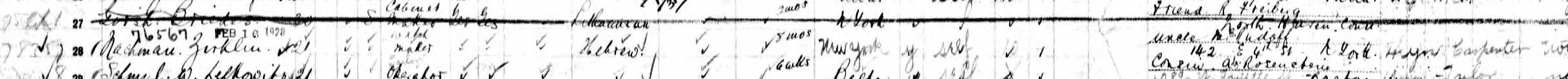
CLICK FOR BIGGER
According to the ship’s manifest, Nachman Zirklin was 21 years old in 1907 – the right sort of age to be the missing brother. He was departing from Liverpool, bound for Philadelphia, PA, and his last place of residence was London, where he had lived for eight months. The immigration date of the Chirklins into the UK was not known but was likely to be around this time. Therefore if this Nachman was the correct person, this record would also give us a likely immigration date for the whole family of around July 1906. Nachman’s birthplace is noted as ‘Lisna’, which is very similar to Disna and an easy mistake to make if the clerk has never heard of the place and has noted down what they thought the person with very little English has said, or indeed if that information is being copied from another document where the upper round stroke of the ‘D’ was very faint.
There was one other very interesting piece of information. Nachman was heading for New York City, where he would be staying with his uncle, a Mr Rudoff. Rudoff, of course, is a phonetic spelling of Rudow, which is, as we knew, the maiden name of Fanny, the mother of the Chirklin family in England. It looked very much like Fanny had a brother in New York, and that her son Nathan/ Nachman was going to stay with him.
As luck would have it, there was another DNA match, estimated 2nd-3rd cousin, to a US-based person with Rudow ancestry. Again the linked tree was very sparse, and while acknowledging the obvious surname link between that family and Fanny back in London, there were no clues at all as to how they might fit in. The earliest known Rudow ancestor on that tree was a Solomon, with an estimated birth year of 1866 and a birthplace of ‘Russia’. However, when I went now to look at this DNA match again I saw that the Ancestry algorithms had been hard at work, and had found a link between ancestors that this match didn’t even have on her tree and two people on the one I had created for the person whose DNA I manage. The two people were Fanny’s parents. I had been given their names by family members and knew nothing more about them. However, Ancestry was suggesting these people were also the parents of Solomon Rudow in New York. If correct, this would make Solomon Fanny’s brother, and therefore the uncle of Nathan/ Nachman.
We should never simply accept hints on Ancestry or any other genealogy website. Hints are suggestions, nothing more. It’s up to us to prove or disprove them. So I now set about researching Solomon Rudow of New York. Through a series of US Federal and NY State censuses I tracked him from his arrival circa 1902 to his death in 1956. On the 1906 US directory I found his address: right next door to that given the following year by Nathan/ Nachman as the address of his uncle Mr Rudoff, on the ship’s manifest. We have our man! This Solomon Rudow is indeed the uncle of Nathan Zirklin/ Chirklin, younger brother of Fanny née Rudow; and Nathan is the son of Marks and Fanny.

This post has looked at how DNA was used to confirm birthplaces, plus connections to two missing people who had emigrated to the USA. In view of the lack of information amongst the living descendants of the Chirklin family, I couldn’t have proven any of this without the DNA.
While in this post we have been looking from England to find out more about people who went to America, in my next post I’ll be staying with Solomon Rudow and Nachman/ Nathan Zirklin/ Chirklin, and investigating what might be learned about the family back in England and their origins in Dzisna/ modern day Belarus by looking at the US records about the two of them.
